Should we switch from rand() to esp_random() on ESP32 and XOR Shift on Libretiny ? #90
Conversation
|
This merge was a mistake - esp32 has a hardware implemented rand(). |
|
I'd assumed you'd already benchmarked the new code and proven it was faster? Before approving #89, I checked the ESP32 hardware RNG API. The documentation clearly states that it will busy-wait if it believes there's insufficient entropy for returning cryptographic-grade random numbers, and rate-limits incoming calls. AsyncTCP doesn't need true randomness for poll throttling - any busy waiting would be inappropriate for this application. The implication is that using the hardware RNG is not appropriate here. It's the old |
|
It busy wait only if called within about 16 us, which I doubt will ever be the case here |
7db4961 to
5c6876c
Compare
b6ac14e to
dc03979
Compare
dc03979 to
54734c8
Compare
|
@me-no-dev @willmmiles PR updated |
I'd expect to hit that any time there are more than two connections open, especially on faster chips. Every timer tick, LwIP loops through the open connections, calling the poll callback for each back-to-back. It's not quite a tight loop but it'll be pretty darn fast, especially if it decides not to queue a poll event for a client. In any event, personally I'd aim for a solution that's got guaranteed good performance rather than hoping our code is slow. |
I agree with this assessment too. How this can be tested ? |
We're firmly in the realm of microbenchmarking on this ...
The key metric is number of loops per |
Why we need all that ? Just a main.cpp compiled with WiFi on (to have some entropy) is enough, then we trigger some calls to rand() and xorshift. We do not need to test within the context of async tcp: we just want to know which one is faster right ? At least, with a loop, we'll see clearly the impact of the busy wait, since it will be exagerated, as if there were many concurrent connections. |
I'm anticipating an argument that |
|
as @willmmiles said. esp_random blocks only if called within 16 microseconds (and up to 16 microseconds) |
|
if the poll is called every 16 microseconds or more, then esp_random will take two register reads + one ccount read + add and compare |
LwIP's poll handler runs infrequently -- but every time it runs, it loops over all open connections and runs the poll callback back-to-back, so |
that's why I wanted to test the worst case: a loop. |
this is not realistic and we know the results already |
In that case, why not use an algorithm that is deterministic and won't risk to slowdown the loop ? I get that this is a trade-off between slowing down a loop that runs infrequently or not. If we favor the 80% use cases where there won't be a loop, then I think we can marge the PR as-is ? Is that ok for you @willmmiles and @me-no-dev ? |
That's not true. There is loop when LwIP calls the |
Ok! So then it goes quite against what @me-no-dev said:
If we have a loop as soon as we have more than 1 connection then this becomes a relevant test and we know the answer and in that case the currently merged implementation will avoid this busy wait. Now, what becomes perhaps more relevant to test is how much time is really lost is such loop compare to an xorshift. Which is why I wanted to test both in a loop (worst case) to see by how much time they differ. If they are close then it means the optimisation is useless and we just merge this PR that rollbacks to esp_rand() for esp32. but if the xorshift allows far more itérations then i think the discussion is closed and we close this PR. @me-no-dev @willmmiles : does it make sense or not ? |
The confounding factor is that I believe that LwIP's poll loop will take less than 16us between calls to |
Thanks! My idea was to quickly find a way to decide what to do by trying to know the relative cost of an xorshift call. What I mean by that is that if a call to xor_shift_next() costs ~10 us, then we just switch back to esp_rand(), no question asked, because this is similar. |
|
Ah, I see! As I'd mentioned above, I'd assumed you already had some measurements identifying |
Yes here is a summary: https://www.perplexity.ai/search/benchmark-de-rand-random-on-es-21pmlAj4TKqCAl33xTQSnw And I did a small benchmark to counter verify these findings because the order of magitude for the differences is huge. #include <Arduino.h>
#include <WiFi.h>
static uint32_t xor_shift_state = 31; // any nonzero seed will do
static uint32_t xor_shift_next() {
uint32_t x = xor_shift_state;
x ^= x << 13;
x ^= x >> 17;
x ^= x << 5;
return xor_shift_state = x;
}
#define CALLS 1000UL
#define SLEEP_MS 0
static uint32_t generated = 0;
static int64_t bench_1() {
int64_t start = esp_timer_get_time();
for (size_t i = 0; i < CALLS; i++) {
generated = esp_random();
#if SLEEP_MS > 0
delay(20);
#endif
}
return esp_timer_get_time() - start;
}
static int64_t bench_2() {
int64_t start = esp_timer_get_time();
for (size_t i = 0; i < CALLS; i++) {
generated = xor_shift_next();
#if SLEEP_MS > 0
delay(20);
#endif
}
return esp_timer_get_time() - start;
}
void setup() {
Serial.begin(115200);
while (!Serial) {
continue;
}
WiFi.begin("IoT", "");
while (WiFi.status() != WL_CONNECTED) {
delay(500);
}
Serial.println("Connected to WiFi!");
Serial.println(WiFi.localIP());
}
static uint32_t last = 0;
void loop() {
if (millis() - last >= 1000) {
#if SLEEP_MS > 0
int64_t dt1 = bench_1() - CALLS * SLEEP_MS * 1000UL;
int64_t dt2 = bench_2() - CALLS * SLEEP_MS * 1000UL;
#else
int64_t dt1 = bench_1();
int64_t dt2 = bench_2();
#endif
Serial.printf("esp_random(): %lu calls in %lld us\n", CALLS, dt1);
Serial.printf("xor_shift_next(): %lu calls in %lld us\n", CALLS, dt2);
last = millis();
}
}Compiled on lastest Arduino Core 3 for esp32dev board with the same pio file we compile our examples. With SLEEP_MS set to 0, so called in a loop, I get (after letting it run for a while): Since our xorshift is even simplified compared to the ones on 64-bits tested in the article, a call in a loop will be 21 times faster. So I did another test, to try figure out what would be the cost of a single call to rand() vs xor_shift if called at interval of 20ms, to avoid this busy wait. With SLEEP_MS set to 20 ms and after accounting for the delays, I get (after letting it run for a while): The first calls to esp_random() or delays (don't know) are costly, but after that, xor_shift_next is still faster by a factor that is unknow. The call costs nothing compared to calling rand(). So to me, in our case we have zero advantage of calling rand(), even if hardware based. We can be highly impacted by teh cost of the busy wait when looping and moreover there is no considerebale advantage also of using it even if not looping. That's why I did not find the need of testing within AsyncTCP... Because the order of magnitude between both is I think significant enough to just decide to use an xor_shift always. |
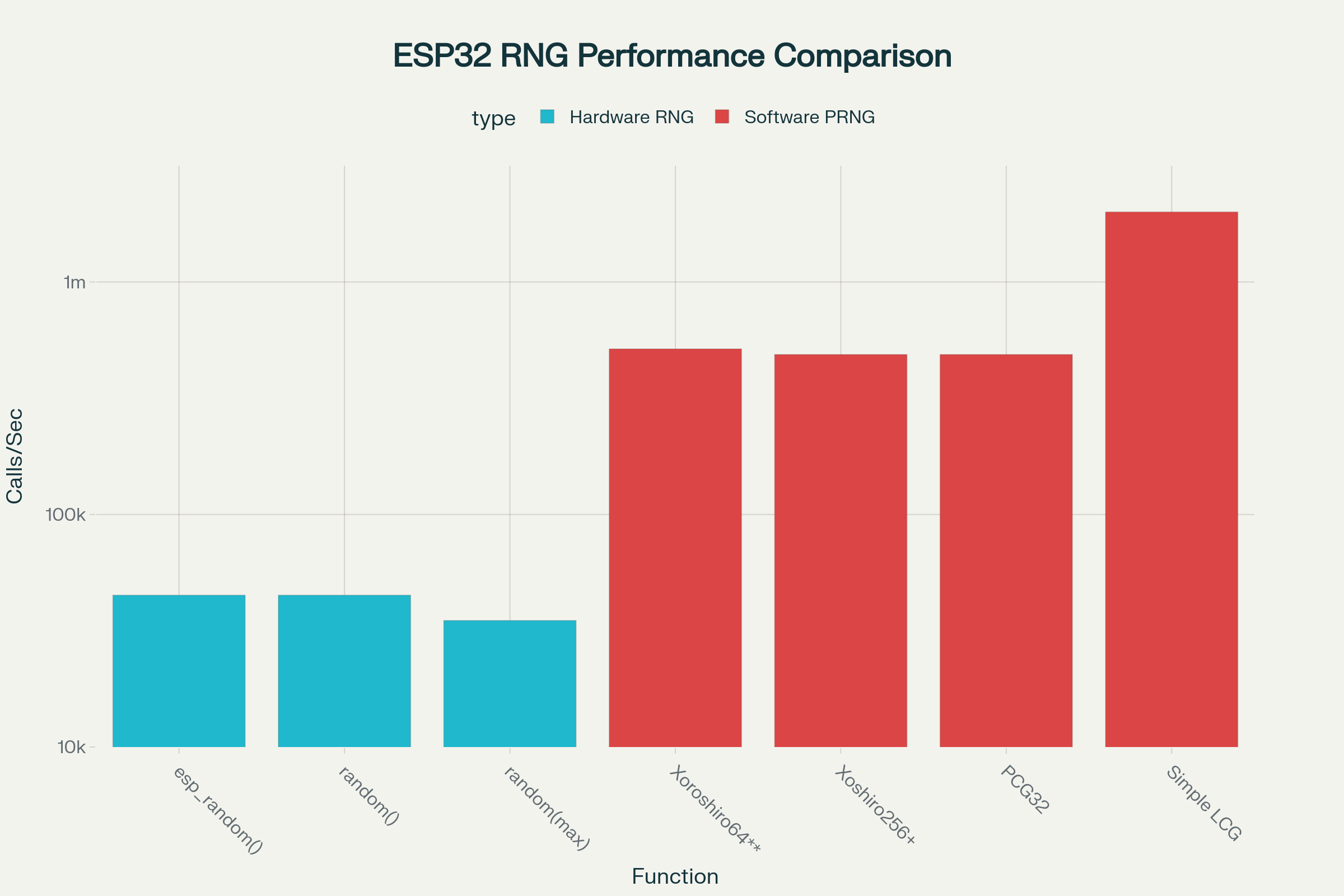
|
I think based on your results that we should probably close this, then. xorshift is good enough; fast; doesn't require any platform selection #ifdefs (a big plus as far as I'm concerned!); and ultimately the long-term solution is to get rid of the stochastic behaviour anyways. |
|
I agree. If @me-no-dev brings up some good arguments in favor of resurrecting this PR, I will do, but for now I concurr we can close the PR and keep the xorshift in main. |
Reverts #89