This program implements and then orchestrates a HashTable to read in a given file, and allow users to interact with the Hashtable via command line.
FIRST: make sure to unzip the dataset files local to the rest of the repo files.
- Ingest data from file
- PUT
- GET
- DELETE
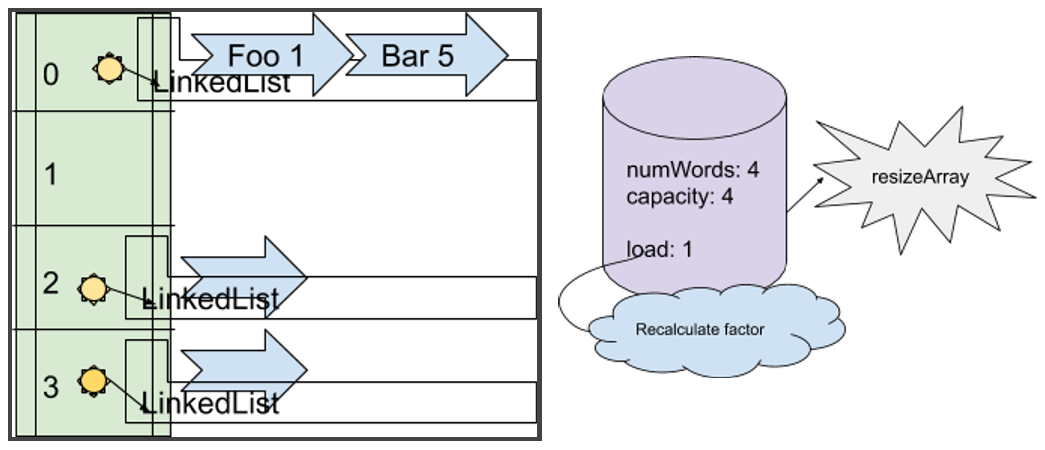
Crucially, the table should resize itself.
Node.cpp, Node.hpp, HashTable.cpp, HashTable.hpp, LinkedList.cpp, LinkedList.hpp, Makefile, main.cpp, test.cpp.
To build and execute test file:
make testfile
Then, run:
./test
For valgrind, run:
make memory
To run main file, simply do:
make build
and then using a given filename:
./database ./dataset_small.tsv
This will run the program. It will ingest the designated file and begin an interactive command line. May take a few minutes to ingest.
Interact with it like so:
:g word to GET a given word
:p word frequency to PUT given word and its frequency to the HashTable, e.g. p: boondoggle 2000.
:r word to DELETE the word from the HashTable, and
:q to quit the program.
Derived from the Tufts U Summer 2019 Data Structures course by Tomoki Shibata and Matthew Russell. Generally, Tufts CS Dept academic policy forbids open sourcing homework unless explicilty stated to the contrary. In this case, the teaching team wrote this homework assignment for one-time use, and I have Tomoki's blessing to open this up.
I ended up rewriting the hash algorithm and got massive results from it, borrowed heavily from this: https://www.programmingalgorithms.com/algorithm/djb-hash?lang=C%2B%2B
The reason this was so much more efficient than prior hashes I wrote was not just the distribution factor (which was about 5x better), but because it ran /quickly/, where my function was just not nearly as fast.
These were really useful:
- Stack Overflow on Arrays of Pointers (1): https://stackoverflow.com/questions/620843/how-do-i-create-an-array-of-pointers
- Stack Overflow on Arrays of Pointers (2): https://stackoverflow.com/questions/47925124/c-dynamic-array-of-pointers
And this as a file i/o user interaction reference: http://www.cplusplus.com/doc/tutorial/files/
I experimented with various loadfactors, settling on 1.0 as being satisfactory for resize. Refactoring at .7 wasn't really giving me many benefits.