![]()
This repo contains a log of my >= 2025 leetcode solves. I was clobbering together the helper scripts for this repo between my solves, so solve times don't go all the way back. Likewise for readiness and topic estimates, they don't go all the way back, however enough data should get collected for progress charts to get increasingly interesting as time goes on.
I can prompt Grok with my entire solve history. As such one of my main uses is to ask for recommdations on what to work on next. This establishes a feedback loop, where not only does it get to recommend what areas i should work on, but in the next round it also sees how well i did.
In short, Grok is in charge of my progress, and gets complete transparency into my performance (code + solve time + notes). Grok keeps on commenting that my solving notes are "pure gold" because of the transparency it gets into my thought process during solves.
I am thrilled with the use of LLMs as learning assistants. The recommendations are of extremely high quality, and the reasoning as to why i should work on what is extremely coherent.
I also could not be happier with the use of Git + Python + LLMs, and believe this workflow (for developers) is not only incredibly versatile, but also extremely powerful.
This approach can be applied to learning any topic.
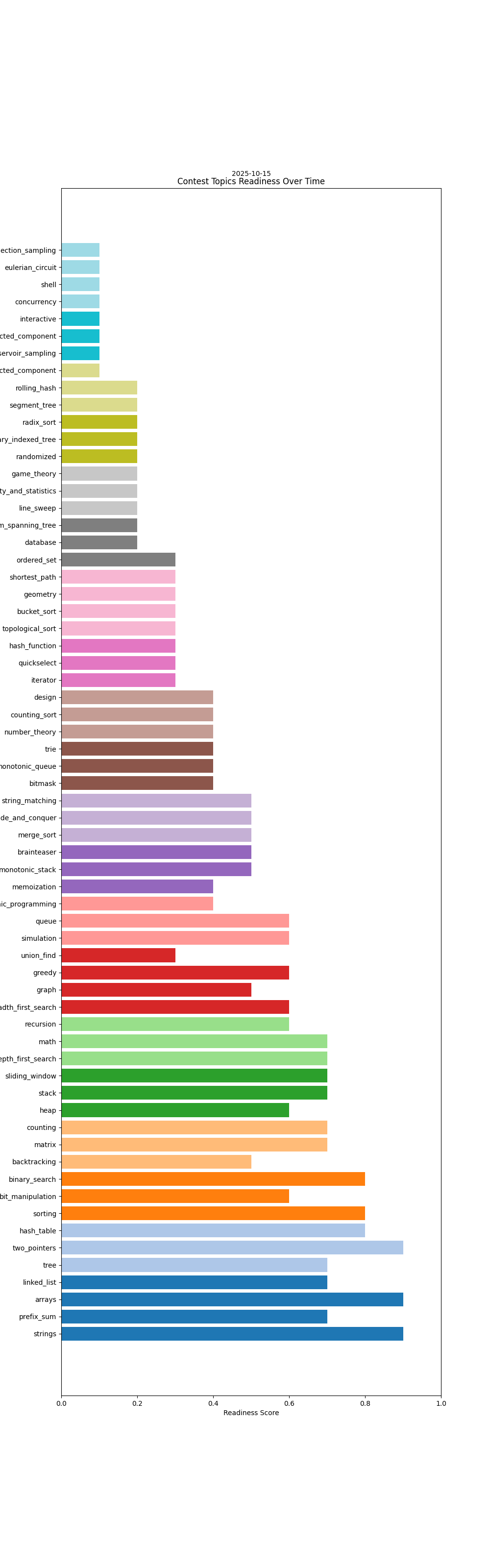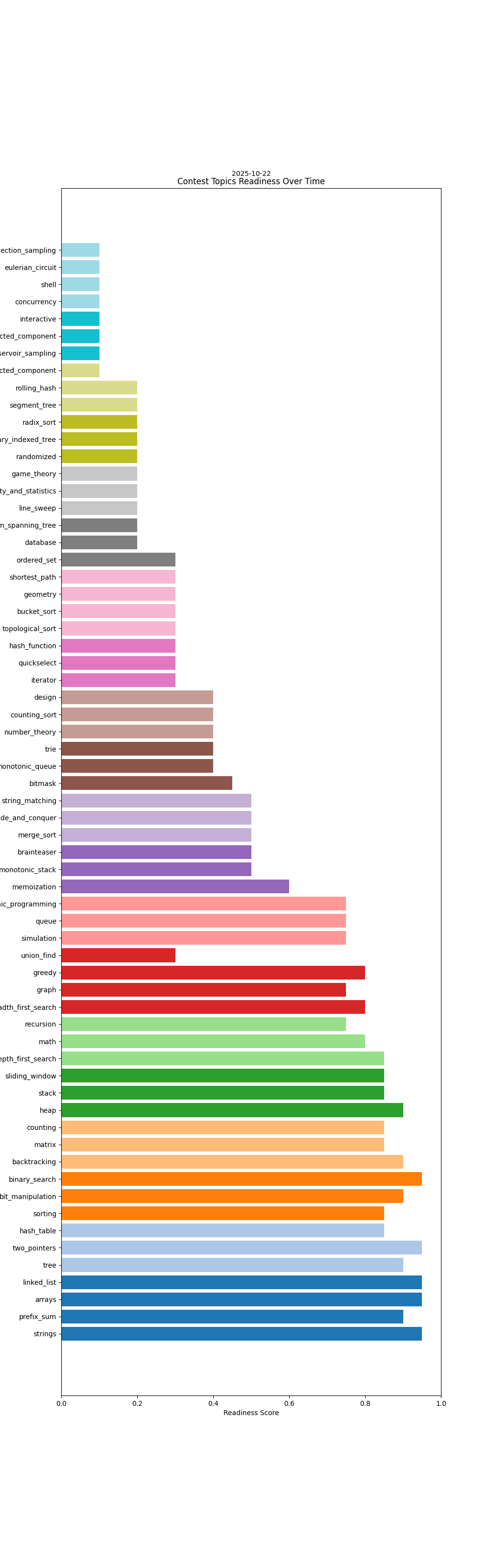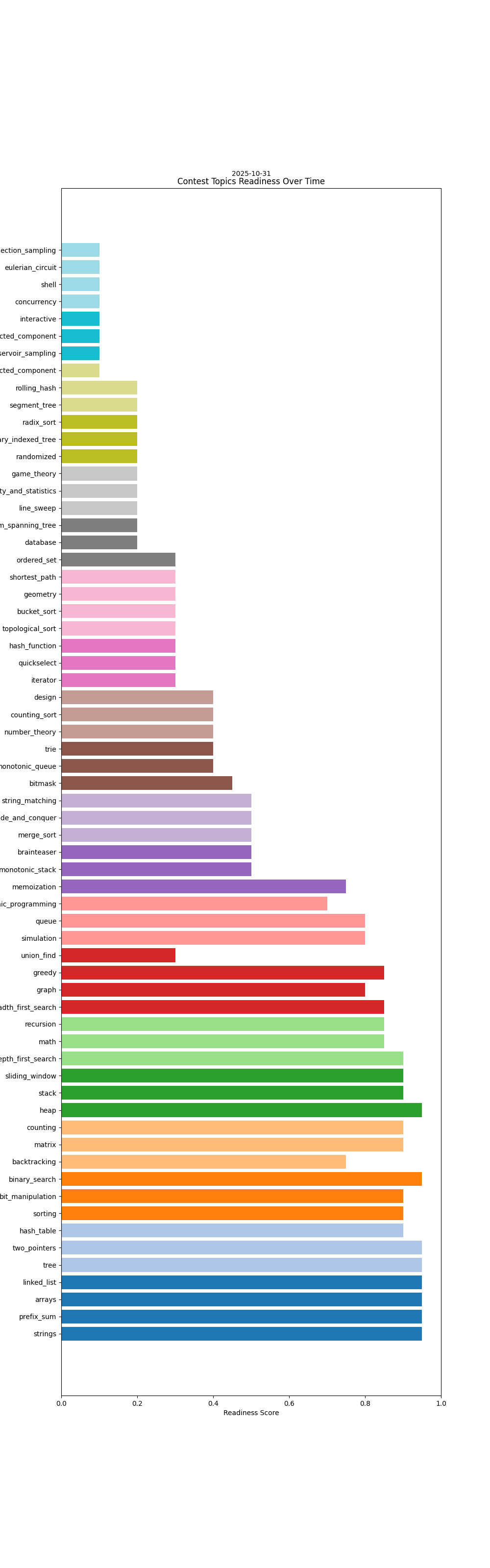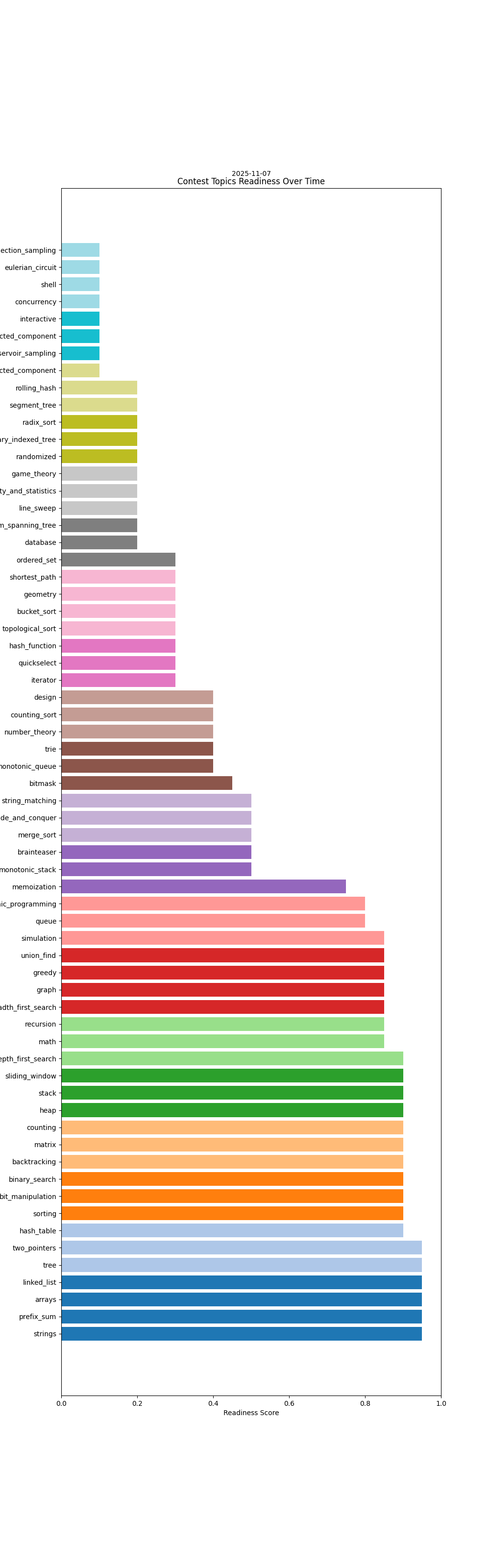
Here are some little charts, generated from the git log.
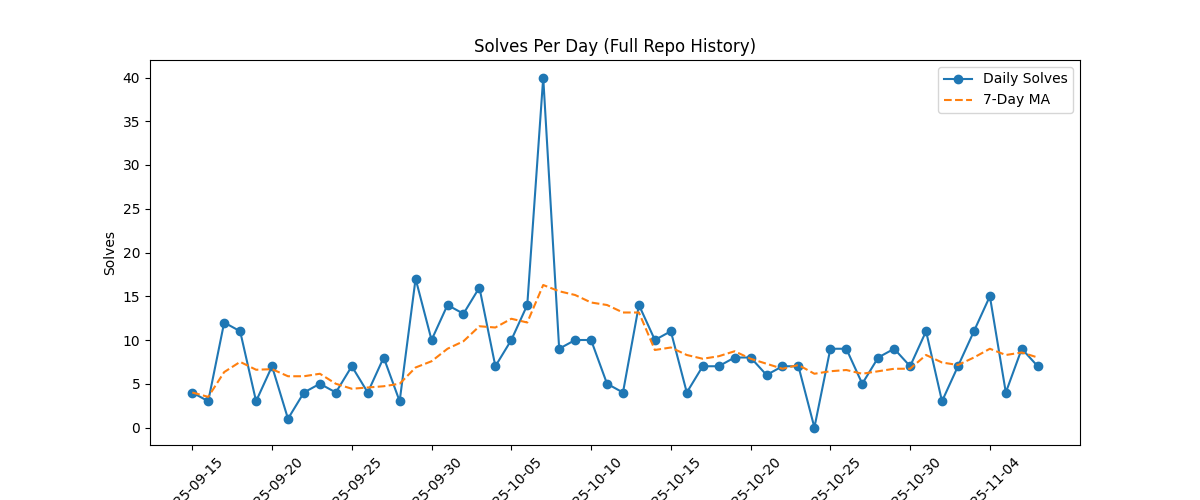
This is the daily solve rate.
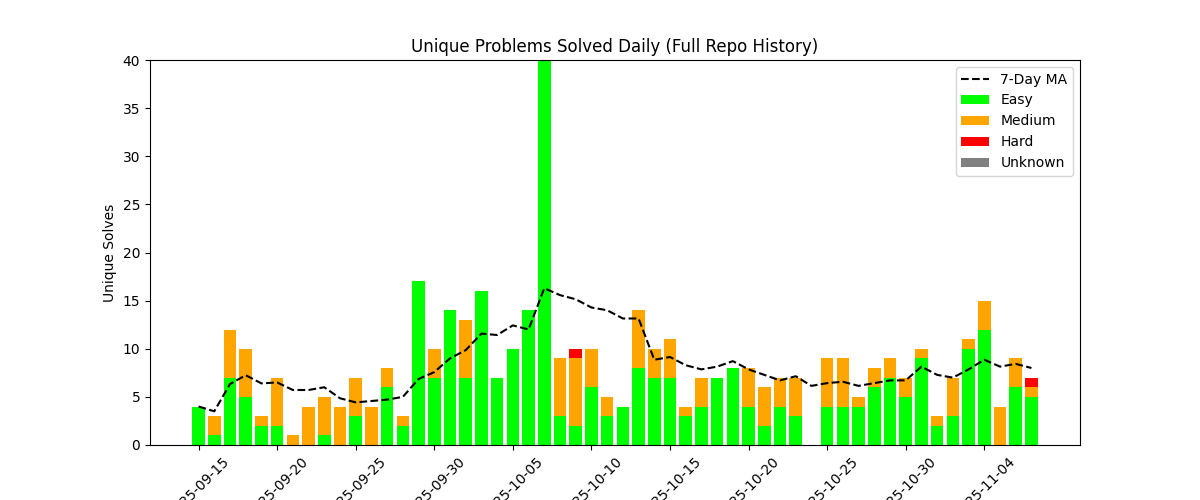
This is the daily unique solve rate. This is because as complexity ramps up, questions will need to be revisited.
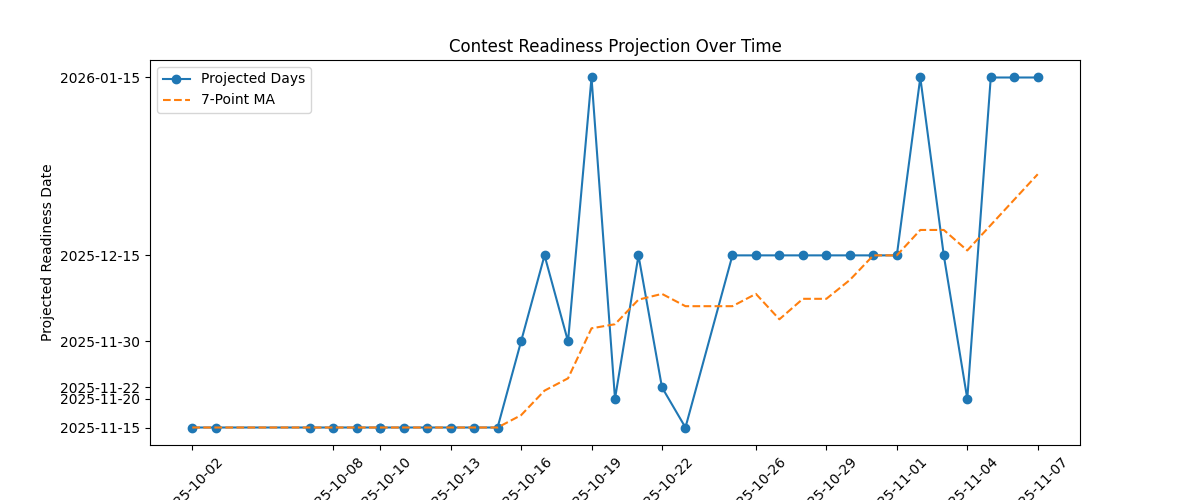
Grok estimates when i'll be ready to take part in leetcode contests.
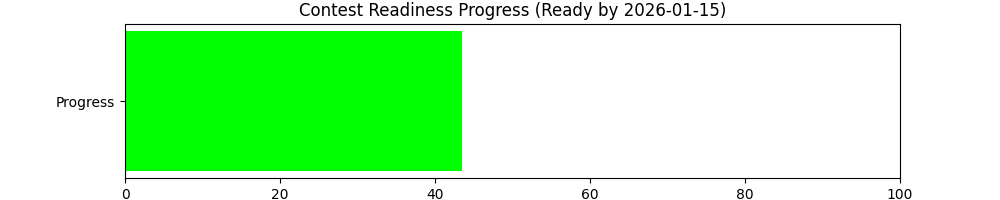
Update: 20-Oct-2025
Initially i was quite stunned by the estimator's tendency to output the exact same dates (without prior knowledge of its previous estimates). Then estimate dates started increasing dramatically. I investigated, and it appears that the estimator heavily weighs recent solves. Initially i was mixing easy and medium questions. The estimates started jumping because i stumbled on quite a few mediums in a row, then focussed on easy questions due to scheduling, and the model assumed this was a sign that my progress on mediums had completely plateaued.
I opted to tackle some of the 'learning' mediums in my history, and this appears to have had a dramatic effect in terms of clawing back those estimate dates.
In other words, these estimate variance charts are excellent indicators for complacency; if i start slacking by doing too many easies, or not tackling my 'learning' queue, estimates go up which is the clearest signal i could hope for.
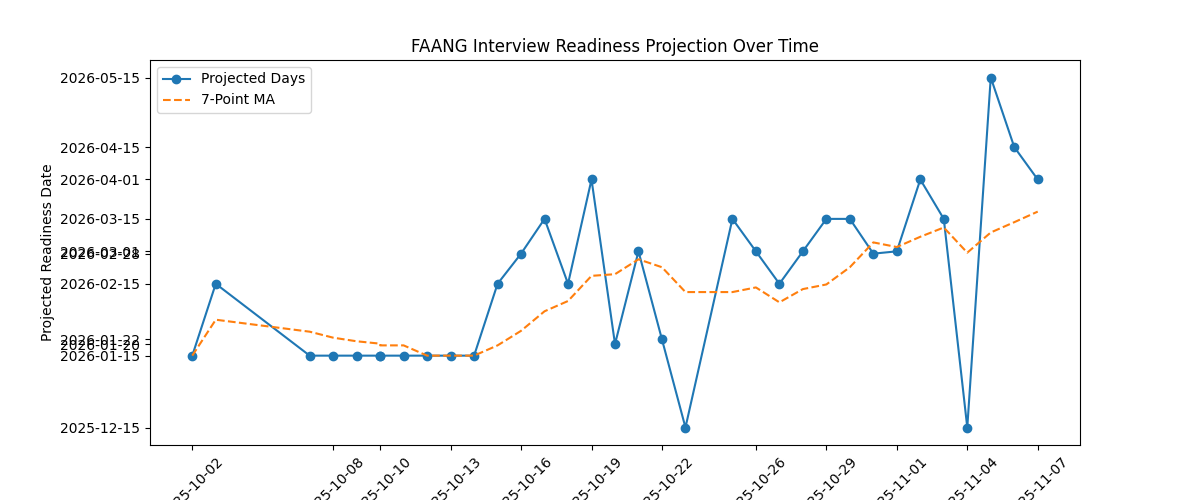
Grok estimates when i'll be ready to pass FAANG mock interviews. Currently the focus of this repo is just fun, but this is an interesting metric regardless.
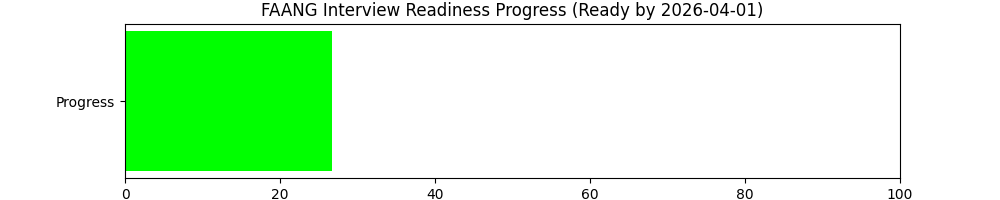
I'm curious to see the amount of variance in the estimates, i.e whether they're stable over time.
Leetcode's python environment is non-standard: it seems to have pretty much everyhing in modules like itertools, functools, bisect, operator etc. readily avialble without the need for imports.
This is really great as it makes writing solutions way faster, without the need to import anything.
This repo tries to reproduce this same environment with utils/sitecustomize.py. It also has a stubs/builtins.pyi for autocomplete to handle this custom import scheme, as well as all the utilities for trees, linked lists, pretty printing etc.
python3 -m venv .venv
. .venv/bin/activate
cp utils/sitecustomize.py .venv/lib/python3.10/site-packages/
pip3 install requirements.txt
PYTHONPATH=./utils:${PYTHONPATH} python3 utils/runner.py
The utility scripts in this repo (for git log reports etc.), solve rate computations etc are LLM generated, so not production quality code (throw away scripts).
Some of the data generated i.e contest readiness dates, topics etc. is also LLM generated.
Solves are all mine. When they're not, i.e 'learning' commits etc. then credit to the author is given (which can include LLM generated solves, credit also given).